
The most capable model is the wrong default, and almost everyone is using it anyway.
Here’s the move I see in every team that’s adopted AI coding agents: they pick the smartest, most expensive model up front “to be safe,” and never touch the setting again. It’s a rational choice. Choosing a model per task is friction, and nobody wants the tool to stall on the one hard problem that actually mattered. So they over-provision. Now they’re paying frontier prices to rename a variable, reformat a table, and fix a typo.
That’s the whole bug, and it isn’t really about code. It’s a procurement habit: when triage feels like overhead, you match the most capable option to every task. It’s flying every employee business class for the commute because sorting out who actually needs it is annoying. The cost doesn’t track the value of the work. It tracks your unwillingness to decide.
The model should follow the work
The fix is obvious once you name it: spend should track the difficulty of the problem. Cheap, fast model for the mechanical 80%. Expensive, frontier model for the hard tail where reasoning actually changes the outcome. A capable mid-tier model for everything in between — and for deciding which bucket a given task falls into.
The catch, at least in Claude Code, is that a session pins one model start to finish. It can’t downgrade itself once it’s reading your prompt. So the only real mechanism for “use the right model for the job” is a router: a working model that reads each task, judges it, and hands the work off to the right specialist.
I built that router and open-sourced it. It’s called overkill.
How it works
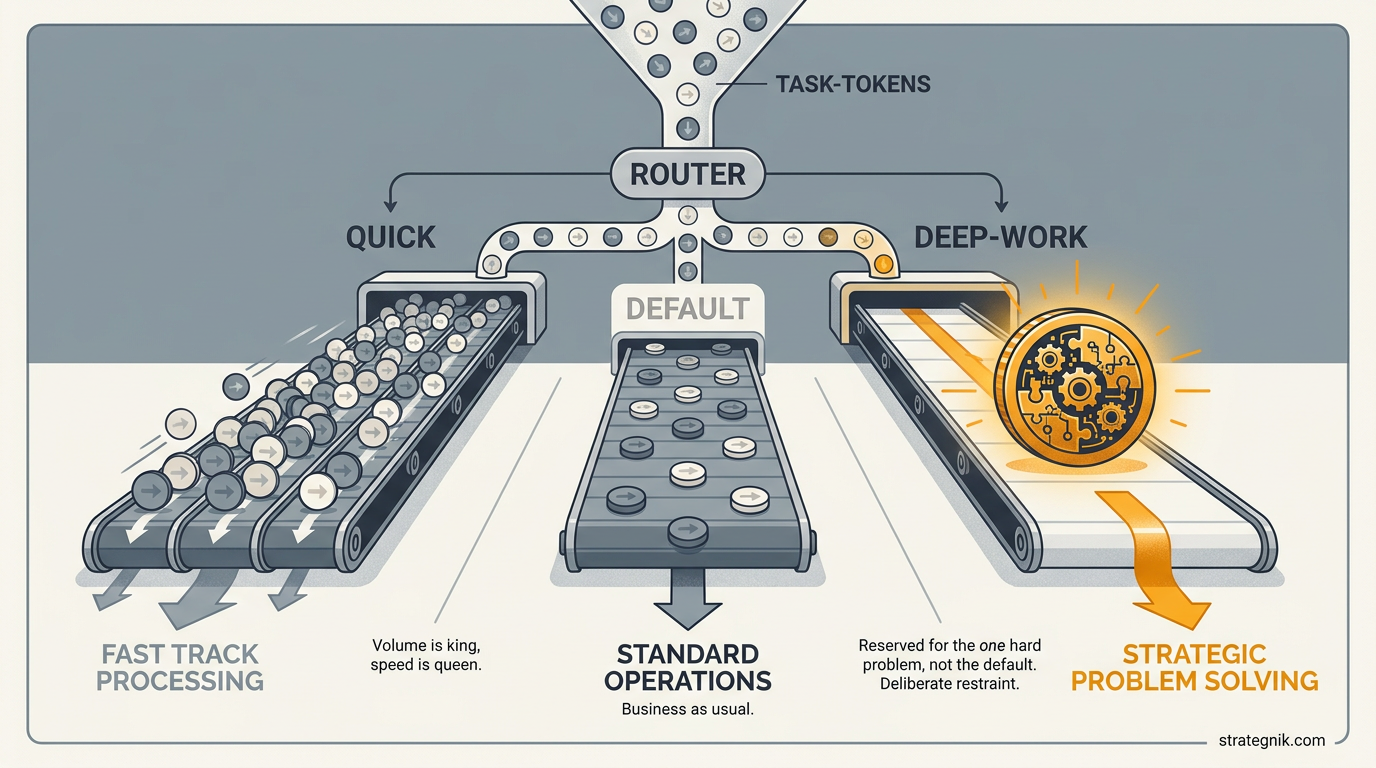
A capable mid-tier model runs by default. It has to read your prompt anyway — so judging difficulty is one beat of that same read, not a separate classifier call with its own latency and cost. As it reads, it routes:
- Mechanical, self-verifying work — renames, copy edits, lookups, boilerplate — goes to the cheapest fast model, at volume.
- Hard reasoning — architecture, optimization, the subtle bug that’s eaten your afternoon — gets escalated to the frontier model.
- Everything else stays with the mid-tier model that’s already doing the reading.
The triage is effectively free, and your bill starts to look like the actual shape of your work instead of a flat top-tier rate. Set it once; every project inherits it; any repo can override it.
That part is a cost story, and it’s real. But it’s not the part I’d defend hardest.
Newer is not better for the job
The reflex when a new frontier model ships is to make it the default immediately. It’s the best one now, so it should run everything. That reflex is the same mistake in a new outfit — letting the most powerful, most expensive option become your floor because deciding is work.
overkill pins specific, tested model versions rather than floating to “whatever’s newest.” A release never silently takes over a tier. Every upgrade is a deliberate decision, and there’s a ritual for it:
Read what the model is actually good at — the announcement, the model card, the stated strengths and the real price and latency, not the vibes. Map those strengths to the jobs you actually have: stronger reasoning is a candidate for the hard-tail tier; cheaper-but-still-capable might shift the default; a better cheap model upgrades the mechanical tier. Then decide the shape, not just the version number — sometimes a model is good enough to collapse two tiers into one, and sometimes the honest answer is to hold because the gain doesn’t clear the cost of switching and re-testing. Run a few real tasks at each tier before you commit. Then log the decision and why.
The most uncomfortable line in that ritual: a better default can make a tier — or the whole router — unnecessary. If a stronger everyday model means you stop reaching for the frontier tier, that’s not a failure of the system. That’s the system telling you the truth. The scaffolding is a liability the moment the model outgrows it, and you want to be the kind of operator who notices.
The actual takeaway
Your AI spend is not a single switch. It’s a portfolio of model-to-task decisions, and the default-to-the-best-one posture quietly makes every one of those decisions for you, badly. The win here isn’t a cheaper model. It’s the discipline of matching capability to task — and re-earning that match every time the lineup changes, instead of inheriting whatever’s newest and most expensive as your standing default.
The tool is a hundred lines of config. The posture is the point.
overkill is MIT-licensed and on GitHub. Clone it, run the installer, start a session. Or just steal the idea: stop paying your smartest, most expensive resource to do your dumbest work.