If you read why your AI is still a chatbot, you know the argument: most companies gave their team AI access and called it a strategy. The actual transformation requires building what I call the Context Layer — the encoded operating context that makes every AI tool, agent, and team member work from the same shared foundation.
This post is the practical guide. What does the Context Layer actually contain? What does each component do? And what does it look like when it’s built versus when it’s missing?
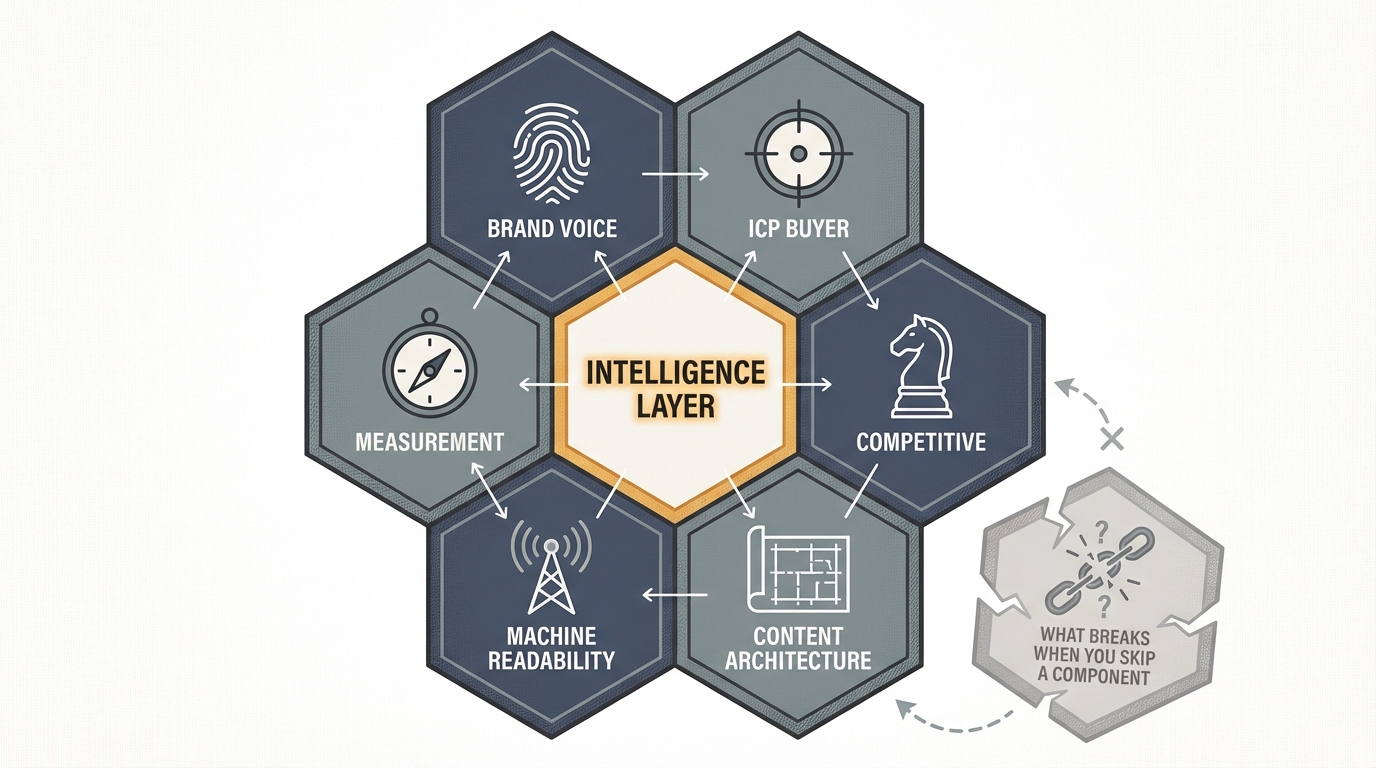
The Context Field has six components. Each one is encoded in machine-readable format — structured context that agents reference autonomously, not a PDF on a shared drive that people forget to check.
But the field serves two audiences most organizations only see one of. The first is obvious: your internal agents and team members. The second is every external machine your buyer consults — ChatGPT, Perplexity, Google AI Overviews, and the autonomous agents that increasingly mediate B2B buying decisions. Internal context engineering makes your AI tools smarter. External signal architecture makes your company legible to the machines that control discovery.
The Context Field must do both. Without the first, your team produces fragmented output. Without the second, your company is invisible to the systems that increasingly decide who buyers talk to.
1. Brand + Voice Spec
What it is: Tone, editorial standards, banned language, writing style rules, voice attributes — encoded so that every agent produces on-brand work without requiring human review of every output.
What built looks like: An agent writes a competitive email sequence. The output matches your brand voice on the first draft — the right level of formality, the right terminology, the phrases you use and the ones you never would. Your team edits for strategy, not for tone.
What missing looks like: Every piece of AI-generated content needs a full rewrite to sound like your company. Your team spends more time editing AI output than they saved by using AI in the first place. Five different agents produce five different voices because none of them know what your voice is.
Why it matters for the physics: Consistent brand voice builds mass — it’s how your external presence accumulates gravitational weight across every touchpoint. When the voice is inconsistent, mass dissipates. Buyers encountering your company across channels get conflicting signals about who you are, and your digital footprint fragments instead of compounding. In the Coherence Model framework, that’s surface area without mass. Wide reach, no gravitational pull.
What most companies have instead: A brand guidelines PDF from 2023 that nobody references. A Slack channel where the content lead corrects tone. An unwritten set of preferences that exist only in one editor’s head.
2. ICP + Buyer Context
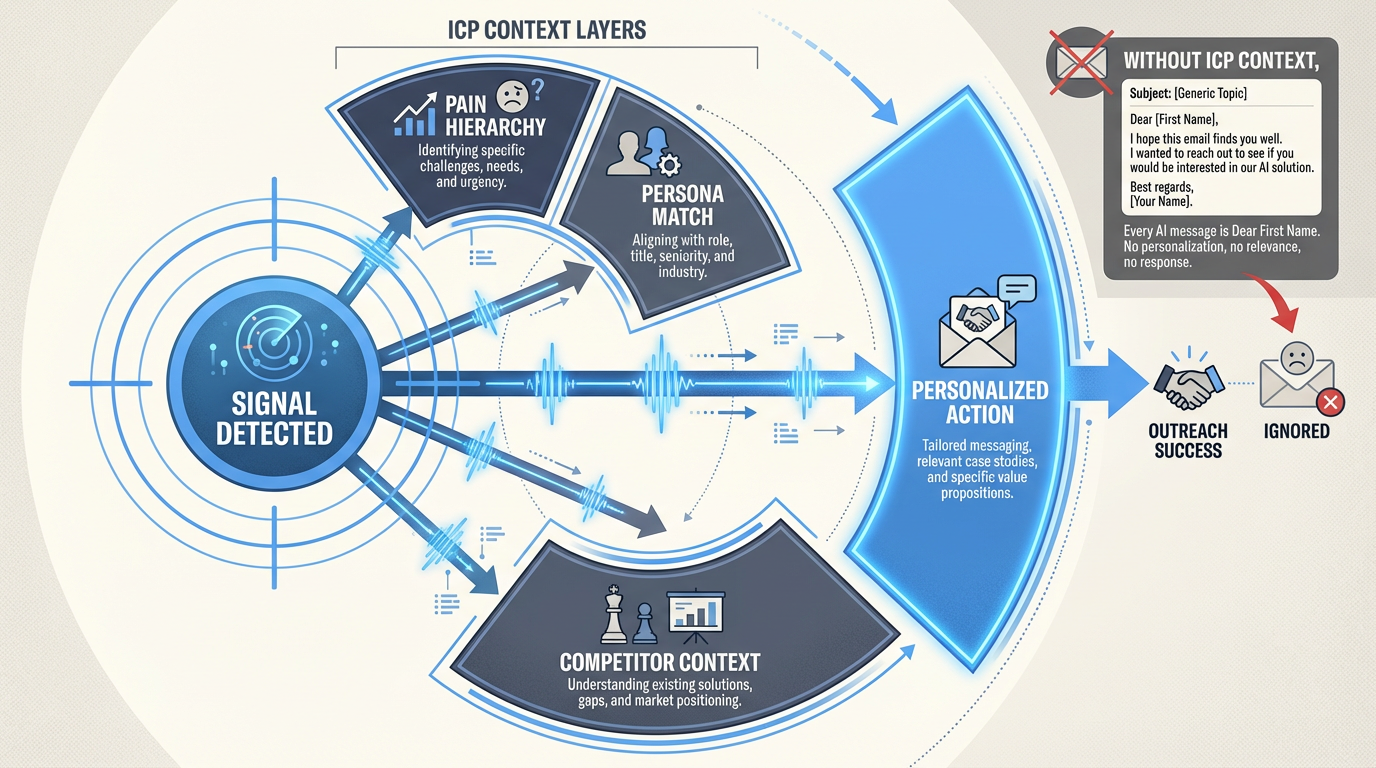
What it is: Ideal customer profiles, buying committee maps, pain hierarchy by persona, objection framing, segment-specific messaging — so agents know who they’re talking to, why it matters, and what the alternatives look like.
What built looks like: An agent receives a signal that a target account visited the pricing page. It generates a follow-up email tailored to the persona who visited, referencing the specific pain point that persona cares about, positioned against the competitor that account previously evaluated. No human had to write the prompt.
What missing looks like: Every outreach piece is generic. “Dear [First Name], I noticed your company is growing.” The AI writes faster, but it writes the same undifferentiated message to every segment because it doesn’t know the difference between your enterprise buyer and your mid-market buyer. Your SDRs still have to rewrite everything.
Why it matters for the physics: ICP context is what makes surface area efficient. Without it, you’re broadcasting into the void — maximum coverage, minimum resonance. With it, every touchpoint is a vector aimed at the right audience with the right message. That’s the difference between noise and momentum.
3. Competitive Framing
What it is: Positioning against alternatives, displacement narratives, win/loss context, differentiated value claims — encoded so every piece of content reinforces your market stance without someone re-briefing the agent every time.
What built looks like: An agent producing a case study knows not to position you as “similar to [Competitor X] but cheaper.” It knows your displacement narrative — the specific reason a prospect should switch from the incumbent and the proof points that make that argument credible. When the competitive landscape shifts (and it will), the framing updates and every connected agent picks up the new context.
What missing looks like: Your blog says one thing about the competition. Your sales deck says another. Your SDR’s cold email says a third. The prospect, who has talked to all three competitors this week, can’t figure out why you’re different because you can’t figure it out either.
Why most companies skip this: Competitive framing is uncomfortable. It requires taking a position. Most brand guidelines stop at “we don’t mention competitors by name.” That’s not a strategy — it’s avoidance. Agents need to know who you’re fighting and why you win. If that context doesn’t exist in the layer, the agent defaults to generic differentiation. Generic differentiation is no differentiation.
4. Content Architecture
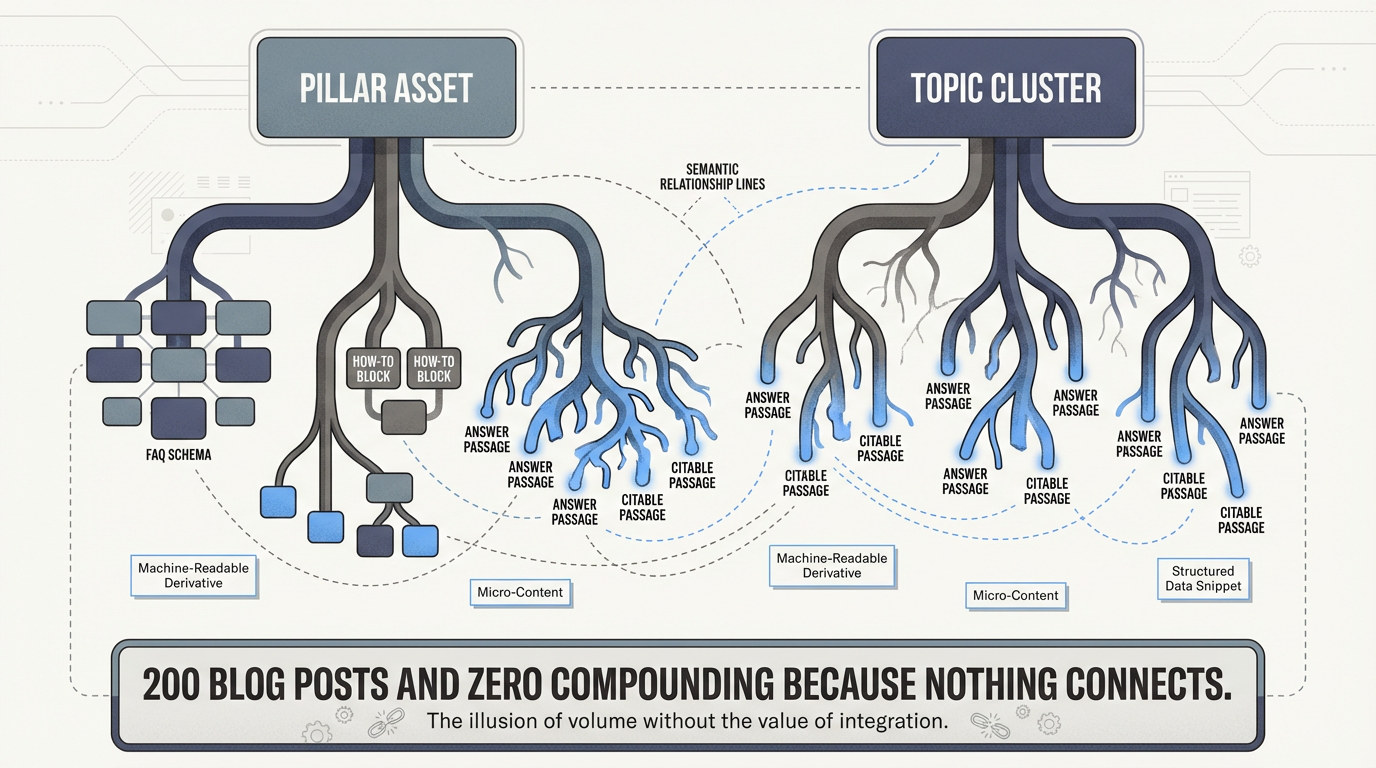
What it is: Topic cluster design with semantic entity relationships. Content atomization frameworks that break every pillar asset into machine-readable derivatives — FAQ schema, how-to schema, comparison tables, passage-level answer blocks. Template structures per content type that embed schema, heading hierarchy, and entity definitions at creation. Internal linking architecture that signals topical authority. Question-answer pair libraries mapped to buying stage.
This is not keyword strategy. It is the structural blueprint for how every piece of content is built so it is simultaneously useful to humans, indexable by search engines, and citable by LLMs.
What built looks like: Every new content asset ships with its structure already defined — heading hierarchy, entity definitions, FAQ pairs, internal link targets, and schema type. The content team (or agent) doesn’t decide the structure. The architecture decides it. The result is a content library where every piece reinforces every other piece, and the whole system is parseable by machines from day one.
What missing looks like: Flat blog posts with no structural relationship to each other. No topic clusters. No internal linking logic. No atomized derivatives. Every piece of content is a standalone island that search engines and LLMs treat as isolated rather than authoritative. Your blog has 200 posts and none of them compound because there’s no architecture connecting them.
Why this component is new: Most Context Field conversations stop at “keyword strategy.” That’s necessary but insufficient. The shift from Google-era SEO to AI-era discoverability requires a fundamentally different content structure — one where the atomic unit isn’t a page, it’s a citable passage. Content architecture is the system that produces passages machines can extract, cite, and attribute.
5. Machine Readability + Distribution Schema
What it is: JSON-LD structured data strategy per page type. Entity definitions — explicitly declaring what the company is, what it does, and who it serves in formats machines parse. AI crawler accessibility via llms.txt specification and robots.txt policy. Multi-surface optimization for Google Search, AI Overviews, Perplexity, ChatGPT, and Gemini. Citation architecture — the source attribution signals that make LLMs treat content as citable rather than paraphrasable.
The difference between being found and being cited is structure. This component ensures the second.
What built looks like: Every page publishes with JSON-LD structured data at creation — Organization, Product, FAQ, HowTo, Article, BreadcrumbList. Your llms.txt file provides a curated overview of the company specifically for LLM ingestion. Your content includes discrete, factual, semantically dense answer blocks that LLMs can extract and cite without losing context. When a buyer asks ChatGPT about your category, the model has structured, authoritative content to reference.
What missing looks like: Your pages have no schema markup. No llms.txt. Your robots.txt blocks AI crawlers (or you’ve never thought about it). ChatGPT doesn’t cite you because your content isn’t built to be retrieved. You’re invisible in the channel that’s replacing the one you spent a decade optimizing for. Human-authored content is 8x more likely to rank #1 and be cited by AI than purely AI-generated content — but only if it’s structured for citation.
Why this is its own component: Machine readability used to be a detail inside SEO. It’s now the primary interface between your company and the machines your buyers consult before they ever contact sales. B2B buyers in 2026 consult LLMs before they consult Google. If your content is not structured for LLM citation, you don’t exist in that buyer’s research process. The pipeline you lost was invisible — it never appeared in your CRM because the buyer never found you.
6. Measurement Targets
What it is: Revenue influence metrics, conversion benchmarks, time-to-personalization goals, decision accuracy signals — so the system knows what success looks like and feedback loops can steer toward it.
What built looks like: The system doesn’t just report what happened. It steers what happens next. A campaign underperforms on a pipeline-influence metric. The layer surfaces the signal. The team adjusts targeting, messaging, or channel allocation — or an agent does it automatically within defined guardrails. The feedback loop is continuous, not quarterly.
What missing looks like: Your dashboards tell you what happened three weeks ago. Nobody acts on the data because it arrives too late and nobody agrees on which metrics matter. You have 47 KPIs in a spreadsheet and no feedback loop connecting any of them to the system that produces the work.
The physics connection: Measurement targets are the steering mechanism — they determine whether momentum is compounding in the right direction or just building speed toward the wrong destination. Momentum without measurement is a car with no steering wheel. You’ll go fast. You won’t go where you need to.
Why You Can’t Build Half the Field
The six components are interdependent. Brand voice without ICP context produces on-brand content aimed at nobody. ICP context without competitive framing produces targeted content with no differentiation. Content architecture without machine readability produces structured content that machines can’t find. Measurement without the other five produces dashboards that track a system nobody built.
This is why the Context Layer is a consulting engagement, not a template. The components have to be built together, for a specific company, in a specific market, at a specific stage. There’s no generic version of your brand voice, your ICP hierarchy, or your competitive position.
And the field doesn’t just serve your internal team. It makes your company legible to every machine your buyer consults. Change it once, and it changes everywhere.
The field is what makes the transition from chatbot to agent fleet possible. Without it, you’re not doing AI-native marketing. You’re doing the same marketing with a faster word processor.
See all 25 Context Field plays in action → Playbook Catalog