There’s a post circulating from an outbound team that just rebuilt their entire context pipeline. Not because it was broken — because it worked too well.
They started with ten context files per client. Generic ICP, catch-all personas, high-level positioning. The simplest approach worked: dump everything into the prompt, cache the static parts, batch the calls. Cost low, latency irrelevant.
Then they got serious. They processed a hundred sales call transcripts through Claude, semi-automatically. Each call produced structured fragments — ICP refinements, persona nuances, specific objections they’d actually heard, proof points grounded in real conversations. They went from a generic “Head of Product” persona to specific buyer segments like “Head of Product at Early Stage UGC Platform.”
The fidelity jumped. And the dump-everything pattern broke.
A hundred context fragments don’t fit in a useful prompt. Even with aggressive caching, signal gets diluted and costs spike. So they built two new layers: a router that selects which subset of context is relevant for a given lead, and a composer that traverses the reference graph between notes — objection leads to proof, JTBD leads to persona, persona leads to insight — and bundles only what matters.
It’s a clean solution. They’re rightfully proud of it. And the pattern they discovered is the most important infrastructure problem in AI-powered GTM right now.
Every team building with AI agents will hit this wall. Most will hit it one client at a time and build one-off solutions. That’s expensive.
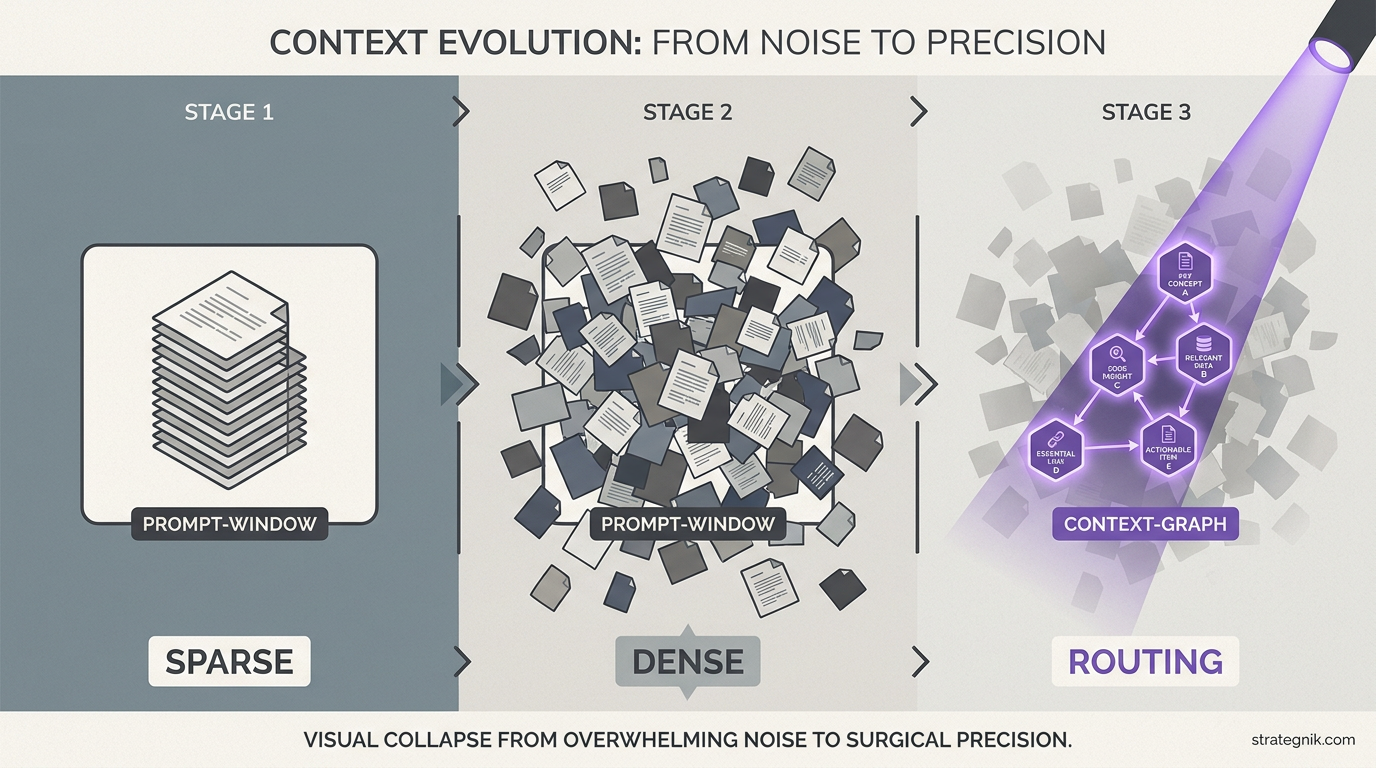
Three stages every team goes through
The progression is predictable enough to name the stages.
Stage 1: Sparse context. You have a handful of documents — positioning deck, ICP overview, maybe a brand guide PDF. The constraint is generating anything useful at all. The fix is straightforward: put everything the model needs into the prompt. Every agent gets the full context dump. It works because there’s not much to dump.
This is where most companies are today. They gave their team AI access and called it a strategy. The agents produce generic output because the context is generic. But at least it fits.
Stage 2: Dense context. Something changes. Maybe you process call transcripts. Maybe you accumulate six months of competitive intel. Maybe a thorough onboarding extracted twenty personas, forty objections, eight competitor displacement narratives, and a hundred proof points. The context is rich. Specific. Grounded. And it doesn’t fit in a prompt anymore.
The team that wrote the original post got here through manual work — a human reviewing each transcript, refining each fragment, promoting the good ones. That’s legitimate. It’s also the path that doesn’t scale to client two.
Stage 3: Routing becomes the bottleneck. You stop tuning the prompt and start architecting retrieval. The question shifts from “how do I give the model enough context” to “how do I give the model the right context.” This is a fundamentally different engineering problem. It requires structure — typed relationships between context fragments, authority levels that distinguish confirmed knowledge from hypotheses, and a routing layer that can explain why it selected what it selected.
The original post nails this: “When context is sparse, the bottleneck is generating good content. When context is dense, the constraint is routing and distilling to the right content.”
Correct. And predictable. Which means you can architect for it from the start.
Why bespoke solutions cost you twice
Here’s where the pattern gets expensive. Every team that hits Stage 3 builds their own version of the same two components: a router and a composer. They build it for their specific use case (outbound sequences, in the original post’s case). It works. Then they add a second use case — maybe content production, maybe ABM personalization — and discover that the routing logic is different for each one.
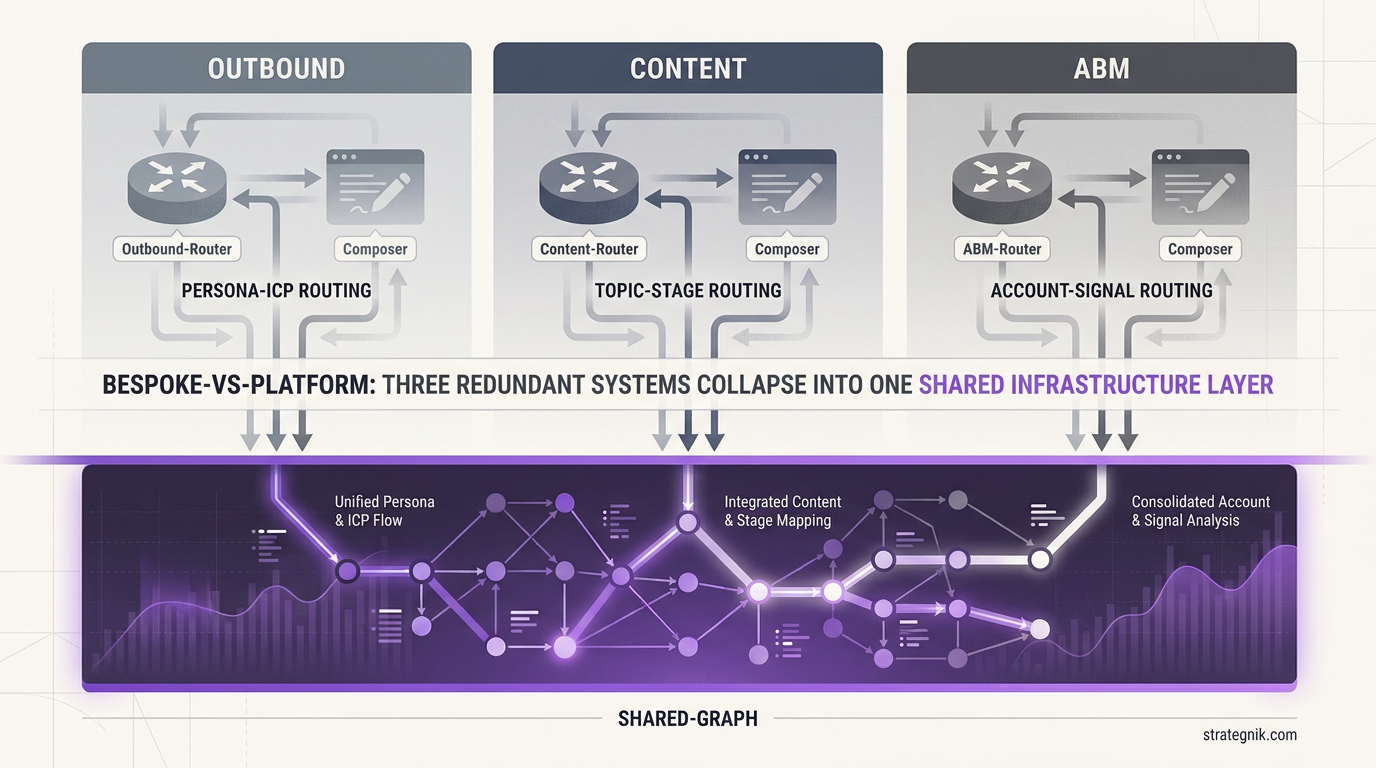
The outbound router selects context by buyer segment (persona × ICP intersection). The content router selects by topic pillar and buying stage. The ABM router selects by account-level signals and competitive displacement angle. Three use cases, three routers, three maintenance surfaces. The code that routes context for outbound doesn’t know how to route context for a blog post. The composer that bundles objection-to-proof chains for a sales email doesn’t know how to bundle competitive framing for a case study.
What started as a clean solution becomes a context routing sprawl. Each new use case adds a new routing layer. Each new client adds a new set of context fragments with different structures. The team that built this for one client now has to decide: rebuild it for client two, or abstract it into a platform?
Most choose neither. They copy-paste the first client’s setup, modify it until it sort of works, and accumulate technical debt that shows up six months later as “why does our AI produce better content for Client A than Client B?”
The answer is always the same: the routing works for A because someone built it for A. It fails for B because nobody did.
What routing as infrastructure actually looks like
The Context Layer we’ve been building at Strategnik was designed for Stage 3 from the start — not because we’re prescient, but because the Afiniti engagement taught us what happens when context gets dense fast.
Three things make the difference between a bespoke router and routing infrastructure.
Typed relationships, not flat documents. Every context fragment in the Context Layer has typed edges to other fragments. A forbidden term links to the brand voice spec it protects. An ICP links to the personas that serve it. A competitive disposition links to the proof points that support the displacement narrative. The router doesn’t search through documents — it traverses a graph. That’s the difference between handing someone a filing cabinet and handing them a map of how everything connects.
Authority hierarchy, not binary inclusion. Not all context is created equal. A positioning statement confirmed by the founder carries more weight than one inferred from website copy. The Context Layer encodes this as an authority hierarchy — codified, working, hypothesis, inferred — and the routing layer uses it to decide not just what to include, but how much to trust it. When the router selects a competitive framing node at hypothesis authority, it flags it: “this displacement narrative is inferred, not confirmed. Use with caution.” The team that built the bespoke router treats all context fragments as equal. Ours doesn’t.
Composability across use cases. The same graph serves outbound, content production, ABM personalization, and compliance validation — because the routing is parameterized by task type, not hard-coded per use case. An outbound composition request routes through persona × ICP intersection to select the buyer segment, then traverses objection → proof and pain → solution edges. A content composition request routes through topic pillar × buying stage to select the relevant cluster, then traverses entity → definition and claim → evidence edges. Different paths through the same graph. One infrastructure investment.
This is what the original post’s author will build next — or should. The bespoke router they built for outbound is the right solution at the wrong layer. It belongs in the platform, not the pipeline.
The acquisition problem nobody talks about
The original post describes how they got to dense context: process a hundred call transcripts through Claude, semi-automatically, with a human reviewing and approving each one. That’s the right methodology. It’s also a hundred hours of operator time per client.
The context routing problem and the context acquisition problem are twins. Dense context creates the routing challenge. But acquiring dense context creates the scaling challenge. If every new client requires a human to review a hundred transcripts before the system produces sharp output, you don’t have a platform — you have a consulting engagement with good tooling.
The answer is the same for both: encode the methodology into infrastructure. Automated extraction pipelines that pull structured context from a company’s website, competitive landscape, customer data, and market signals. Semi-automated review flows that present hypotheses for human confirmation instead of requiring humans to generate from scratch. Completion checklists that verify the graph is dense enough to route well before declaring a tenant live.
The team that goes from “we manually built a hundred context fragments for one client” to “the system automatically discovers and structures context for any client” has something worth selling. The team that stays at “we do it manually and it’s really good” has a services business.
Both are fine. But they’re different businesses with different ceilings.
Where this is going
The original post ends with a prediction: “I think this will keep happening as agents accumulate institutional knowledge. The first thing you build is ‘load the context.’ Eventually you have to build ‘find the right context.’”
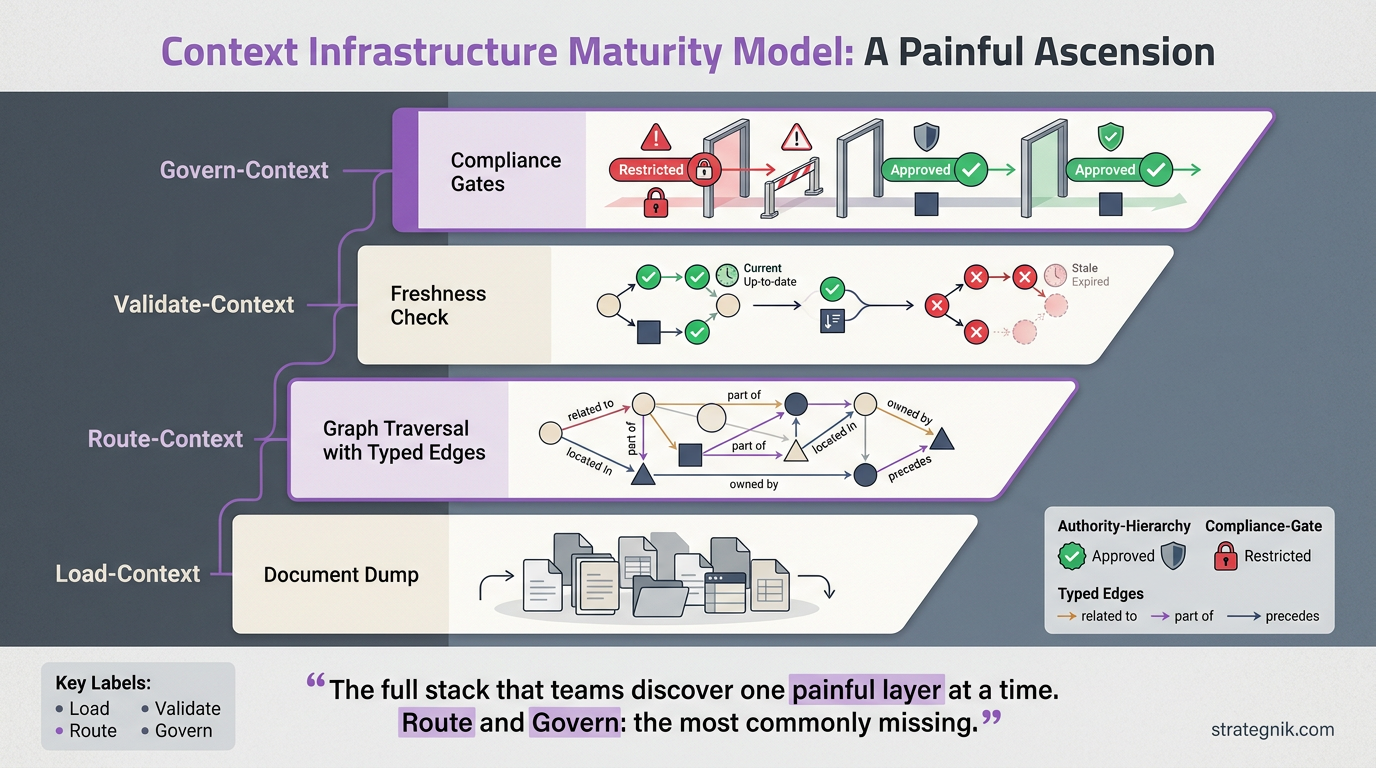
I’d go further. The next bottleneck after routing is validation — how do you know the context you routed is still accurate? Competitive landscapes shift. ICPs evolve. Proof points expire. A routing layer built on stale context is worse than no routing at all, because it delivers wrong answers with high confidence.
After validation comes composition governance — not just “did we select the right context” but “did the output comply with the rules encoded in that context?” The forbidden term that should never appear in customer-facing content. The competitive framing that’s approved for sales but restricted from public marketing. The proof point that’s valid for one vertical but inapplicable to another.
Each of these — routing, validation, governance — is a component of what we call the Context Layer. Each one is a problem that every team hits in sequence as their context matures. And each one is dramatically cheaper to solve at the platform level than to rebuild per client.
The post that inspired this piece is a field report from Stage 3. It’s accurate, well-observed, and correctly identifies the inflection point. The question for every GTM team reading it isn’t “should we build a router?” — you’ll have to eventually. The question is whether you build it as a one-off, or as the foundation for everything that comes after.