The Situation
The marketing team had all the tools. Salesforce for CRM. Marketo for automation. DemandBase for ABM and intent data. LinkedIn Ads for paid targeting. Four platforms, significant annual spend, and a dashboard that could tell you anything you wanted to know.
Except it couldn't tell you which accounts were actually likely to buy.
The propensity model existed—technically. But sales didn't trust it. "Your 'hot' leads are garbage," was the polite version of the feedback. Marketing would point to the data showing high intent scores. Sales would point to the conversations that went nowhere.
Both were right. The model was mathematically sound. It was also practically useless.
I was brought in to fix demand gen, but within the first two weeks, it became clear that the problem wasn't campaigns or content or targeting. The problem was data.
The Insight
Propensity models are only as good as the data feeding them. Garbage in, garbage out—everyone knows this. But the failure mode I found wasn't garbage data. It was inconsistent data.
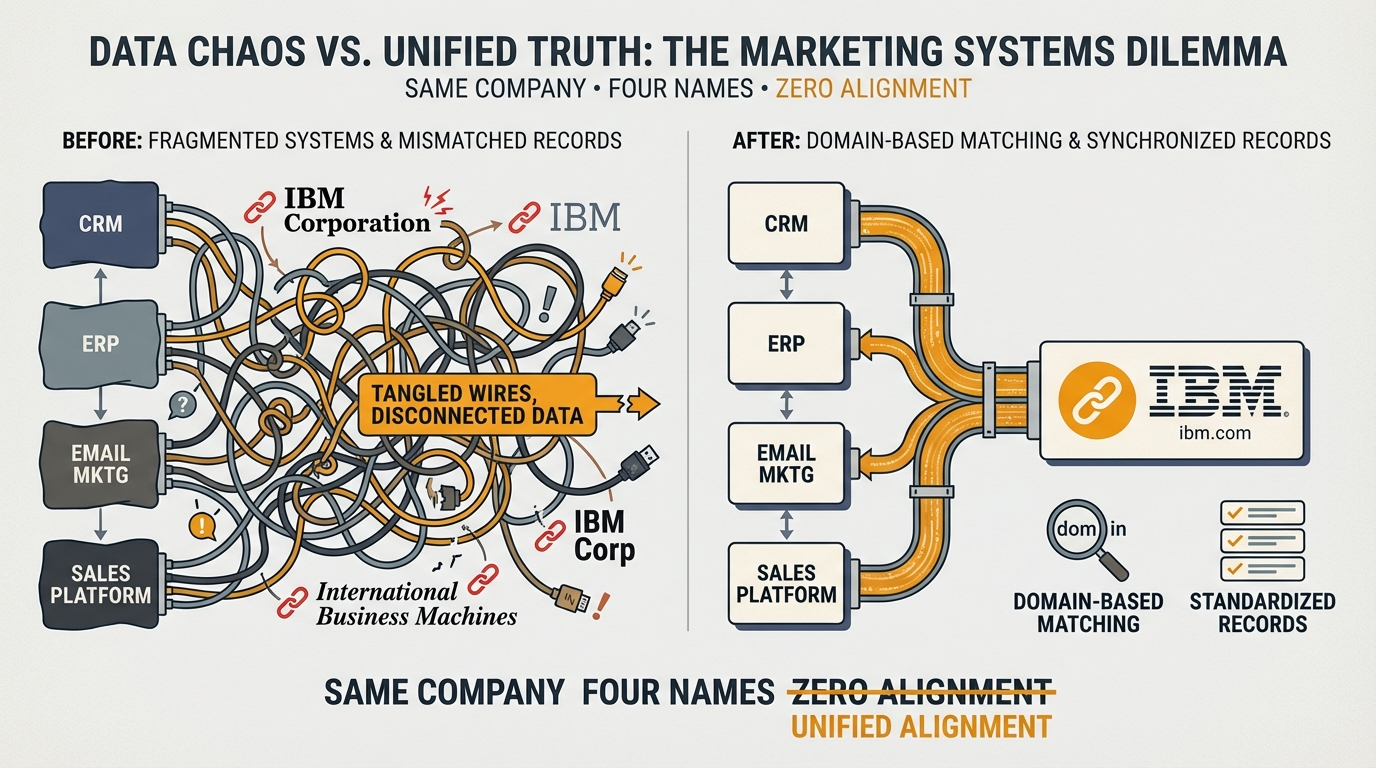
The four systems had been implemented at different times by different teams with different naming conventions:
- Salesforce had "IBM Corporation" as an account. Marketo had "IBM" and "IBM Corp" as separate records. DemandBase had "International Business Machines."
- Industry classifications didn't match. Salesforce used a custom picklist. DemandBase used SIC codes.
- The same contact might exist in three systems with three different titles.
- Intent signals from DemandBase weren't consistently flowing to Salesforce.
The model was mathematically weighting data—but it was doing math on records that weren't actually the same entities.
The insight: The prediction problem was actually a data governance problem.
The System
Layer 1: Data Audit and Mapping
First, we mapped every field across all four systems. The output was brutal:
- 47 fields that should have been synchronized
- 23 fields with naming inconsistencies
- 12 fields with conflicting data types
- 3 systems with no automated sync
Layer 2: Standardization Rules
Company Identification
- Primary key: Domain name (most reliable unique identifier)
- Secondary matching: Legal entity name with fuzzy matching
- Standardization: All company names normalized to D&B format
Industry Taxonomy
- Standard: Adopted DemandBase industry categories as source of truth
- Mapping: Built translation tables from SIC codes and Salesforce picklists
Layer 3: Integration Architecture
DemandBase (Intent Data)
|
|---> Salesforce Account (nightly batch + real-time for surges)
| |
| \---> Marketo (account-level intent visible in automation)
|
LinkedIn Ads
|
|---> Marketo (engagement tracking)
| |
| \---> Salesforce Lead/Contact
|
Marketo (Behavioral Data)
|
\---> Salesforce (bi-directional sync, 15-minute intervals) Layer 4: The Propensity Model
With clean, synchronized data, we rebuilt the scoring model:
Input Signals (weighted by predictive power):
- Firmographic: Industry alignment, employee count, tech stack, geography
- Behavioral: Website visits by page value, content downloads, email engagement
- Intent: DemandBase surge scores, keyword research, competitor signals
- Historical: Similarity to closed-won accounts
| Score Range | Classification | Sales Action |
|---|---|---|
| 80-100 | Sales-Ready | Immediate outreach, high priority |
| 60-79 | Marketing Qualified | Accelerated nurture, SDR qualification |
| 40-59 | Engaged | Standard nurture, monitor for surge |
| 20-39 | Aware | Light-touch digital, brand awareness |
| 0-19 | Cold | Exclude from active campaigns |

Layer 5: Vertical Segmentation
Rather than one model to rule them all, we calibrated for high-value verticals:
Banking/Financial Services: Heavier weight on compliance content, longer lookback window
Retail: Seasonal adjustment, customer experience content weight, peak period multiplier
The Takeaway
Most companies don't have a prediction problem. They have a data problem masquerading as a prediction problem.